Назначение
Во время чтения человек сравнивает буквенный текст со своим словарным запасом.
Подобным образом работают программы, осуществляющие Парсинг (Parsing, англ.).
Этим термином в информатике обозначается синтаксический анализ, для проведения которого на языке программирования создаётся математическая модель.
Тогда программа, запущенная компьютером, сравнивает набор конкретного текста со словами из интернета и выдаёт результат в каком-то удобном виде. Именно такие программы называют парсерами.
Отсюда понятен алгоритм его работы:
- Выход в интернет;
- Просмотр/обработка информации;
- Подведение/выдача итоговых данных.
Для получения результатов парсера его можно заказать или делать самостоятельно с использованием купленных или бесплатных приложений.
Для бесплатного (!) поиска и составления слов-ключей относительно своего веб-проекта удобно воспользоваться приложением «Словоёб» (хотелось бы посмотреть в глаза маньяку, давшему такое название).
Однако в любом случае для того чтобы приложение правильно работало — нужно всё верно настроить.
ВАЖНО. Бесплатный «Slovoeb» ограничивается Яндексом.
С чего начать
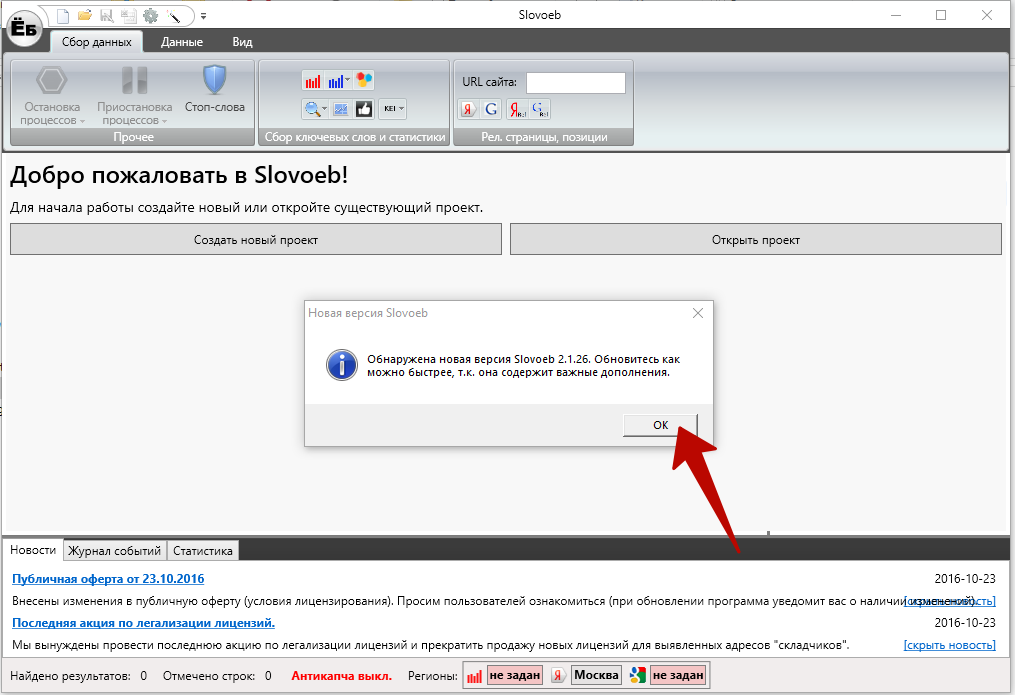
2) Запустите скачанный файл, чтобы установить программу на компьютер. Обновите до новой версии, если выходит такое окно:
Далее переходим к настройке программы Словоеб.
3) Зайдите в «Настройки» в левом верхнем меню, которое появляется при нажатии значка программы:
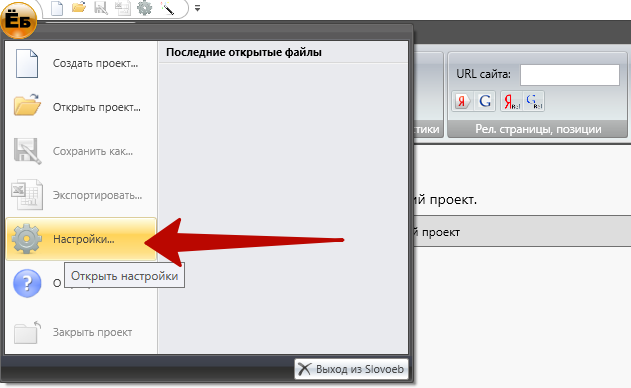
4) В разделе «Парсинг» задайте его параметры. Уберите значок «+» из поля «Фильтрация символов». Остальное оставьте, как задано по умолчанию.

Не забудьте сохранить изменения (далее сохраняйте их отдельно на каждой вкладке).
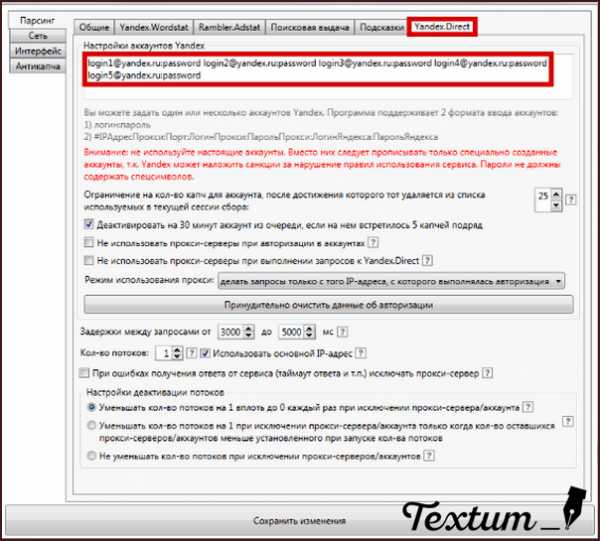
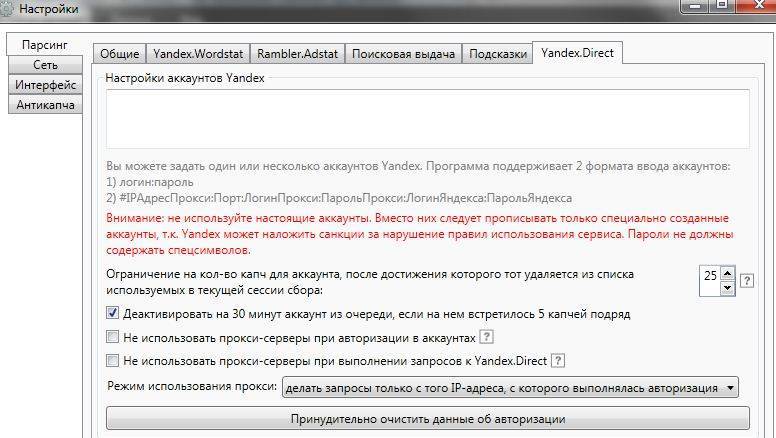
5) Настройте аккаунты Яндекс.Директа специально для сбора семантики.
Обратите особое внимание на следующее. Использовать нужно специально созданные под парсинг аккаунты, проще говоря — «фейковые»
Пусть вас это не пугает: Яндекс лоялен к парсерам, так как с помощью них рекламодатели могут настроить более качественные рекламные объявления, что на руку самой системе — ведь она на этом тоже зарабатывает. Это с одной стороны
Использовать нужно специально созданные под парсинг аккаунты, проще говоря — «фейковые». Пусть вас это не пугает: Яндекс лоялен к парсерам, так как с помощью них рекламодатели могут настроить более качественные рекламные объявления, что на руку самой системе — ведь она на этом тоже зарабатывает. Это с одной стороны.
С другой — рабочий аккаунт, в котором ведется реклама, использовать ни в коем случае нельзя. Яндекс может его забанить за нарушение правил пользования сервисом. В этом случае лучше рискнуть потерять доступ к «фейковому» аккаунту, а не к настоящему.
Итак, далее придется выполнить небольшую рутинную работу по регистрации почтовых ящиков аккаунтов в Яндексе.
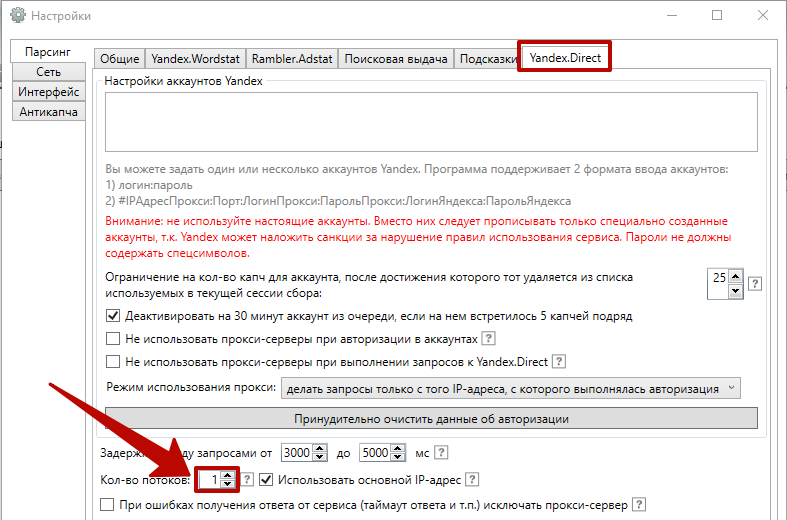
Важно! Несмотря на то, что аккаунты «фейковые», задавайте им читабельные имена пользователей, чтобы впредь процесс не тормозили капчи Яндекса, и работа продвигалась быстрее. Затем перейдите на вкладку «Yandex.Direct» и в поле «Настройки аккаунтов Yandex» задайте их, а здесь введите их логины и пароли в любом из форматов
Чем больше, тем лучше, но достаточно и 3-5 аккаунтов
Затем перейдите на вкладку «Yandex.Direct» и в поле «Настройки аккаунтов Yandex» задайте их, а здесь введите их логины и пароли в любом из форматов. Чем больше, тем лучше, но достаточно и 3-5 аккаунтов.

В поле «Количество потоков» впишите количество созданных аккаунтов:
6) Ту же самую цифру задайте на вкладке «Yandex.Word»:
7) В разделе «Интерфейс» на вкладке «Экспорт» выберите, в каком формате будете экспортировать результаты парсинга:

Дополнительно можете подключить автораспознавание капчи, чтобы она вас не преследовала. Особенно если вы планируете парсить большие объемы ключей. Стоимость сервисов по автоматическому распознаванию символическая, актуальные цифры смотрите в разделе «Антикапча» по ссылкам:

На этом основные настройки парсинга готовы, Словоеб готов к сбору данных. Переходим к самому процессу.
Как работать в программе
Теперь мы кратко разберемся, как пользоваться этой программой. Сложностей тут никаких нет. Но все равно стоит дать небольшую инструкцию, которая будет включать в себя последовательность действий и обзор некоторых функций.
Для начала вы должны создать проект. Идем в главное меню (кнопочка Еб в углу), нажимаем на “Создать проект”. Выскочит окно нашего файлового менеджера, где нам будет предложено заполнить поле “Имя” и сохранить наш файл проекта в каком-то месте.
Это все делается на ваше усмотрение. Но лучше сохранять проекты в той же папке, где и сам Словоеб. После того, как вы кликнете “Сохранить”, проект откроется в окне программы.
В нижней части программы мы видим настройки регионов для Яндекса и Гугла. Самая первая отвечает за Яндекс.Вордстат, вторая – за Директ, третья – Гугл. Также тут есть кнопка обновления, которая поможет вам в случае, если программа начнет тупить.
Чуть выше вы можете видеть вкладки: “Новости” – которых уже не было 2 года, “Журнал событий” – лог всех операций, производимых через утилиту, и “Статистика” – тут будет отображаться статистика по собранным ключевикам.
Еще выше у нас расположилось большое поле, где будут все запросы и их частотности. Вся информация представлена в виде удобной таблицы.
Рядом “Управление группами”. С помощью этого инструмента вы сможете разбивать запросы на группы и работать уже с ними.
В самом верху у нас находятся инструменты для работы с семантическим ядром. Самая первая из доступных нам кнопок позволяет работать с минус-словами. Туда можно вписать слова и фразы, которые программа должна игнорировать при сборе ядра.
Рядом идут инструменты для работы с Вордстатом и поисковыми подсказками. Вы можете собрать ключи из левой колонки Вордстата (с наличием самого ключа в запросах), правой колонки (похожие запросы). После этого можно собрать поисковые подсказки или проверить корректность словоформ. Здесь же инструменты для вычисления KEI и сбора частотностей.
Для добавления своих поисковых фраз вы должны перейти во вкладку “Данные”, нажать на кнопку “Добавить фразы”. У вас выскочит окно, куда вы сможете ввести одну или несколько поисковых фраз.
Поисковые фразы можно добавлять в текущую группу, либо же создать новую. Также вы можете воспользоваться функцией “Загрузить из файла”. Программа работает только с TXT-файлами, поэтому если вы сохраняли поисковые фразы где-то еще – самое время перенести их в блокнот. После этого вы сможете собрать частотности или провести любые другие операции с этими данными.
Как только работа по сбору семантического ядра и очистке его от лишнего мусора будет закончена, вы должны экспортировать всю информацию в файл. Для этого найдите в левом верхнем углу иконку с Excel-файлом и кликните на нее. Далее вновь откроется окно файлового менеджера, используя которое вы и сохраните файлик с таблицей.
Вы можете сохранить проект и вернуться к работе над ним позже. Для этого нажмите на иконку сохранения, также выберите папку через файловый менеджер и кликните на “Сохранить”.
Сравнение приложений Словоеб и Кей Коллектор
Первым свет увидел Словоеб. Далее программа обросла дополнительным функционалом, обзавелась новым названием – Кей Коллектор и стала продаваться с годовой подпиской за 1800 рублей, на момент написания данной статьи.
С 2016 года Словоеб не обновлялся и сегодня по-прежнему имеет версию 2.0. Вторая версия получала немного более расширенный функционал, были исправлены ошибки и некоторые аспекты работы с ключевыми словами. Если вы не профессиональный СЕО специалист, то данной проги вам будет предостаточно. Поверьте мне на слово!
На сайте производителя приведена таблица отличий этих двух программ.
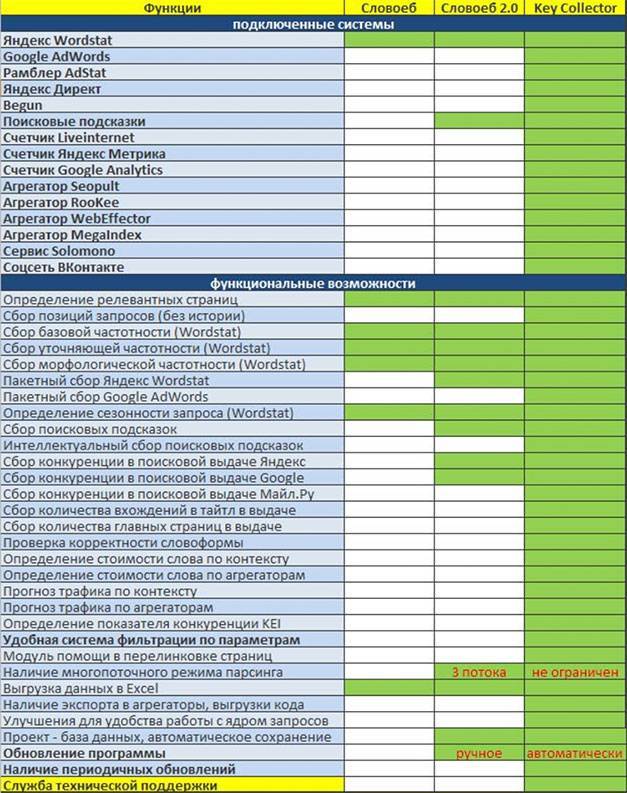
Видно, что Словоеб работает преимущественно с Яндекс-Вордстатом и поисковыми подсказками. КК имеет намного шире возможности и функционал в целом. Ну, собственно, поэтому он и платный.






Для продвижения в Яндексе проги SlovoEB будет предостаточно. Она поможет вам собрать семантическое ядро для блога.
Также КК умеет работать с множеством сервисов:
Эти сервисы предоставляют доступ к своим алгоритмам поиска ключевых слов, статистики, конкуренции, определяют примерную стоимость продвижения, показывают количество рекламных объявлений по запросу и т.д.
Приступаємо до налаштування Slovoeb’а
Завантаження його можна зробити з офіційного сайту (http://seom.info/new/SlovoEB).
Установка не потрібно – розпаковується в будь-яке місце архів і запускається виконуючим файлом Slovoeb.exe.
Перед налаштуванням потрібно запам’ятати каталог, де будуть ці настройки зберігатися і ознайомитися з правилами підбору ключових слів – так як, само собою, це дуже важливо для подібної програми.
Отже, після запуску бачимо вікно:
Перед початком роботи створіть кілька акаунтів на Яндексі
Також перед налаштуванням рекомендовано створення хоча б п’яти-шести акаунтів на Яндексі, так як буде потрібна обов’язкова авторизація (Спецсимволи в паролі не допускайте).
Під час роботи програми здійснюється потужне кількість запитів до пошукової системи від ваших акаунтів. У відповідь на це можна нарватися на повідомлення про те, що обліковий запис викреслять зі списку. Тому не використовуйте реальні свої адреси (явки):
Щоб уникнути блокування робочих акаунтів, використовуйте спеціально створені кілька клонів
ВАЖЛИВО.
Входимо в настройки.
вкладка Yandex.Direct
На вкладці Yandex.Direct здійснюється введення значень логіна і пароля через двокрапку (ознайомившись з попередженням на вкладці).
ВАЖЛИВО.
Парсінг.Общіе
Значення, зазначені на картинці, змінюються з виходом оновлень (маються на увазі значення за замовчуванням). Крім того, ці параметри потрібно погоджувати “під себе”. Але при відсутності досвіду оптимальними будуть запропоновані самою програмою.
Пояснення параметрів видно з іншого малюнка:
Пояснення до параметрів програми
Яндекс.Вордстат
У цій вкладці:
- Значення глибини виставляється нуль.Значення “одиниця” призведе до виникнення перевантаження системи і довгого очікування. При встановленні значення 2 – після основного парсинга програма приступить до глибинного аналізу по кожному з ключових слів. Це призведе до блокування IP-адреси;
- Максимальна кількість парсіруемих сторінок;
- Опрацьовуються сторінки від тисячі показів на місяць до ста (на спадання);
- Вводиться логін / пароль через двокрапку;
- Зберегти зміни.
Підказка для вкладки “пошукова видача” представлена на зображенні:
Приклад заповнених значень
Налаштування антікапчі
Важливий момент – розпізнавання капчі. Для того щоб від неї позбутися потрібно скористатися додатковим сервісом. Утиліта підтримує такі:
- Antigate;
- SocialLink;
- CaptchaBot;
- ruCaptcha;
- RIPCaptcha.
Перший видається більш класичним, платним (проте недорогим). CaptchaBot – більш сучасний.
Відшукати їх можна за такими адресами: antigate.com і anti-captcha.com.
Вхід в налагодження антікапчі відбувається Клацання мінімізує вкладку лівій частині вікна налаштувань.
Ключ антікапчі, отриманий в її настройках, потрібно ввести в поле “Antigate Key”:
Введіть отриманий код
Інші вкладки:
“Мережа” і “Підказки” залишаємо недоторканими, інтерфейс налаштовується виходячи з власних уподобань.
Парсинг поисковых фраз в Словоебе
Познакомившись с интерфейсом этой замечательной программы и проставив все нужные настройки, пора переходить к процессу парсинга поисковых запросов из сервиса статистики Яндекса. Далее я расписал пошаговый план сбора будущих ключевых слов в Словоебе. Для примера использовал данные Вордстата по запросу «инфобизнес».
Создаем новый проект (или открываем готовый). В самом начале парсинга нужно сделать свой проект, в котором будут находиться нужные нам поисковые фразы по заданным словам. Обычно каждый проект у меня называется по одной теме.
Указываем стоп-слова. Если мы знаем, какие слова мы не хотели бы видеть в спарсенных поисковых запросах, то их необходимо прописать. Например, для коммерческого сайта этими словами будут «бесплатно», «халява», «скачать» и т.д. Таким образом мы облегчаем процесс сбора будущих ключевиков.
Выбираем регион продвижения. Для того, чтобы получить реальные параметры спарсенных поисковых запросов, необходимо задать нужный регион (аналогичный в сервисе Вордстат). Например, если Ваш блог продвигается по всей России, то в программе необходимо назначить такую же географическую область. Обычно я использую регион «Москва» или «Россия». В данном примере взят второй вариант. Выбрав регион, нажимаем левую кнопку парсинга Вордстата (кнопка №5) и получаем таблицу данных с поисковыми запросами и базовыми частотностями:
Фильтруем полученные запросы. Когда процесс сбора всех поисковых запросов закончился, мы должны пробежаться по ним и удалить те фразы, которые не подходят для нашей тематики. Поверьте, в каждой теме таких слов бывает достаточно. Но их обязательно нужно удалить, потому что они никак не дадут нам ключевые слова для продвижения нашего блога. Чтобы удалить их, сначала надо их выделить в таблице (с помощью чек-боксов):
Затем подводим мышку к нашей таблице с поисковыми фразами, нажимаем ее правую кнопку и в выпадающем меню выбираем соответствующую команду удаления:
Таким образом на выходе мы получаем уже тематические слова по нашим заданным фразам со своими базовыми частотностями. Теперь можно получить и другие параметры поисковых фраз, благодаря которым мы сможем выбрать самые качественные будущие ключевые слова.
Собираем точные частотности. На этом этапе парсинга нашей задачей является получение уточняющих параметров запросов от пользователей поисковых систем — они будут нужны при отборе качественных ключевых слов. Для этого нажимаем кнопку по сбору частотностей (на картинке интерфейса — элемент под номером 7) и выбираем из появившегося меню строку «Собрать частотности !» (картинка справа).
Удаляем слова-пустышки. После того, как в таблице данных наши спарсенные поисковые фразы получат свое значение точной частотности, необходимо удалить из нее так называемые слова-пустышки (точная частотность которых крайне мала и обычно имеет значение от 0 до 2). Удалить можно таким же способом, который показан выше по тексту.
В итоге мы получаем таблицу с данными частотностей для каждого полученного из поиска запроса. Теперь можно сделать ряд дополнительных действий (узнать конкуренцию по версии Словоеба, определить самую релевантную страницу по каждому ключевику) или экспортировать полученные поисковые фразы для дальнейшей обработки.
Таким образом, мы прошли весь процесс парсинга левой колонки Вордстата. Если нам необходимо для расширения тематики узнать дополнительные слова, можно воспользоваться парсингом правой колонки (процесс сбора запросов там такой же, какой мы сейчас рассмотрели).
Минус-слова Словоеба
Теперь мы поговорим о таком термине, как «минус-слова» (стоп-слова) и о том, как работать с ними в Словоебе.
Минус-слова (стоп-слова) – это слова, которые нам не нужны. Их используют для упрощения работы со списком ключевых фраз, которые соберет Словоеб.
Например: если у вас информационный сайт, и вы ничего не продаете, вам не нужны ключевые фразы со словом «купить»; если у вас сайт по предоставлению услуг в Москве, то вам не нужны ключевые слова, которые содержат другие города.
Чтобы добавить стоп-слова в Словоеб, нужно:
- Нажать на соответствующую кнопку на панели задач.
- Добавить слова.
- Закрыть окно.
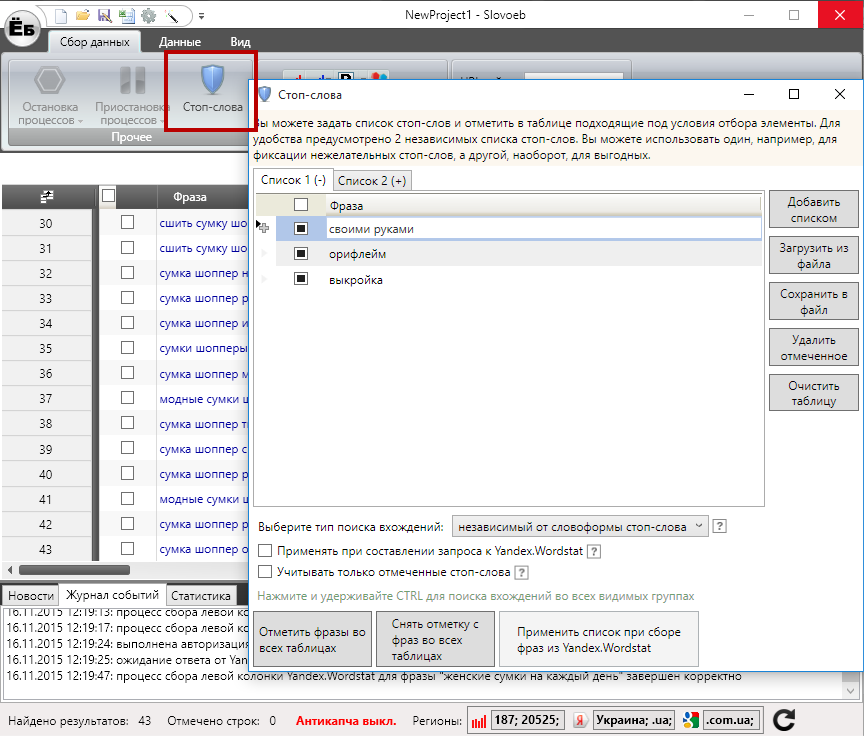
Теперь «Словоеб» не будет добавлять в таблицу фразы, в которых встречаются отмеченные слова.
Стоп-слова можно добавлять пакетно (файлом) или сохранять, что в свою очередь бывает весьма необходимо.
В случае если вы уже собрали все нужные вам фразы, но стоп-слова сразу не прописали – не беда, сделайте следующее:
- Внесите необходимые стоп-слова.
- Нажмите кнопку «Отметить фразы во всех таблицах».
Теперь все фразы в таблицах, в которых присутствуют стоп-слова, отмечены галочками.
- Закрываем окно стоп-слов и возвращаемся к нашему списку фраз.
- Вызываем контекстное меню и выбираем «Удалить отмеченные строки».
Только что мы очистили наш список от всех фраз, которые содержали стоп-слова (минус-слова).
Как работать с программой словоеб?
После установки программы (ссылка на скачивание ниже), вы открываете програму и перед вами появится примерно вот такое окно:

Вы кликаете “новый проект”, называете его и указываете путь, куда сохранить на вашем компьютере.
Далее указываете свой главный запрос в строке “запрос” и нажимаете ентер:
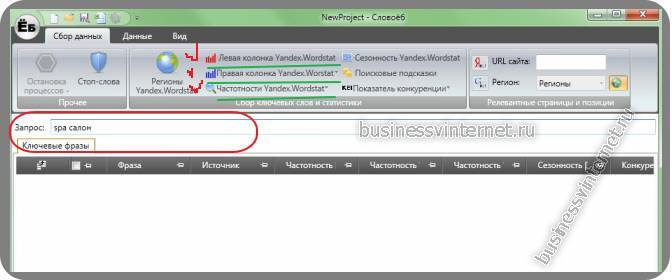
Спустя какое то время – перед вами готовый результат. Далее, чтобы оценить настоящую частотность поискового запроса (вида: “!ключевое слово”), кликаете собрать частотность вида “!слово”:

Перед вами полная картина потенциальных поисковых запросов, которые вы можете использовать.
Я в качестве главного запроса выбрал “spa салон”. Это достаточно “широкий” запрос.






Но можно выбрать из множества результатов 10-20 ключевых слов, который и взять за основу (план) для написания статьи.
Если ничего не нашли подходящего в таком списке – выполните поиск по правой колонке яндекса (или поставьте другой главный запрос, отражающий тематику будущей статьи).
Результат поиска ключевых слов в программе словоеб.
https://www.youtube.com/subscribe_widget
После того, как отобрали 10-20 ключевых слов для статьи, рекомендую их проверить в статистике https://adwords.google.com.
Ведь в Яндексе они могут быть просто накручены seo оптимизаторами (люди, которые составляют семантическое ядро например).
Поэтому, вы вбиваете свои запросы (которые отобрали для написания статьи) в гугл для анализа. Если Гугл показывает нулевые показатели, то запрос “накрученный” и его надо заменить.
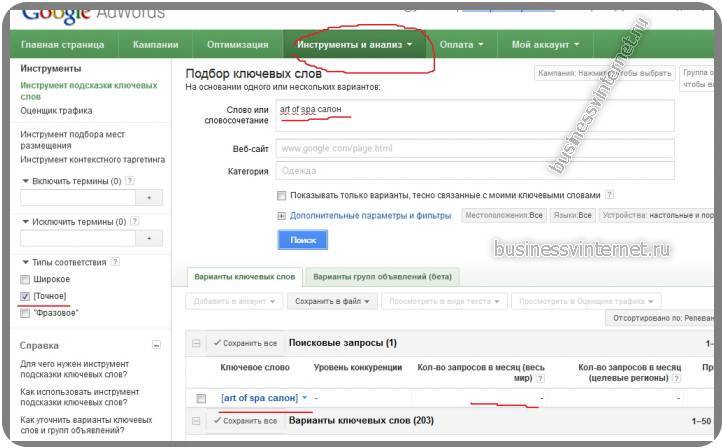
Также рекомендую использовать сервис семраш (_http://ru.semrush.com/) для оценки стоимости клика по контекстной рекламе.
Вот что у меня получилось в Словоеб (данные только из левой колонки Яндекса):
spa салон | 11236 | 647 |
салон красоты spa | 1133 | 8 |
spa салон отзывы | 742 | 7 |
spa салоны москвы | 600 | 300 |
спа салон spa | 532 | 1 |
абонемент в spa салон | 452 | 383 |
салон spa deluxe | 289 | 6 |
spa салон массаж | 268 | 6 |
spa салон beauty spa | 228 | 53 |
spa салоны спб | 172 | 72 |
art of spa салон | 162 | 41 |
thai spa салон | 152 | 7 |
spa салон desheli | 149 | 46 |
spa deluxe салон красоты | 147 | 42 |
салон day spa | 141 | 1 |
игра spa салон | 130 | 62 |
spa салон челябинск | 119 | 61 |
spa салон услуги | 115 | 6 |
салон spa deluxe тверская 18 | 115 | 59 |
spa cocteil спа салон | 101 | 11 |
spa салон цены | 100 | 5 |
art of spa салон отзывы | 94 | 66 |
1с spa салон | 90 | 14 |
spa салон екатеринбург | 89 | 39 |
массажный spa салон | 88 | 1 |
spa салон пермь | 85 | 29 |
мужской spa салон | 81 | 22 |
day spa салон красоты | 79 | 41 |
spa cocktail салон | 79 | 51 |
сертификат в spa салон | 75 | 9 |
spa салон для мужчин | 75 | 31 |
spa салон донецк | 73 | 26 |
салон красоты beauty spa | 72 | 10 |
spa салон grand | 71 | 14 |
spa салон подарочный сертификат | 65 | 8 |
spa салоны нижнего новгорода | 64 | 25 |
spa салоны новосибирск | 62 | 18 |
spa салон 7 красок | 57 | 13 |
spa салоны красноярск | 57 | 30 |
vita spa салон | 57 | 4 |
spa салон для двоих | 56 | 25 |
spa салоны алматы | 56 | 21 |
spa салон ростов | 56 | 6 |
spa салон краснодар | 55 | 2 |
салон spa relax | 54 | 6 |
spa салон самара | 53 | 19 |
spa салон харьков | 50 | 22 |
spa салон зеленоград | 48 | 6 |
spa салон киев | 47 | 26 |
spa салоны тюмень | 46 | 21 |
Где скачать и как установить
Скачать последнюю версию программы можно на официальном сайте разработчика seom.info. Не бойтесь, никаких вирусов и троянов там нет. Также можете почитать блог автора, он там частенько делиться полезными фишками и опытом в продвижении. Короче разберетесь.





Скачиваем архив, распаковываем его на свой ПК. Программа не требует установки, единственное для ее работы необходимо установить .NET Framework 4.0, если он у вас еще не установлен. Ссылка также есть на сайте производителя.
Для любителей продукции Apple новости печальные. Для работы Словоеба придется заморочиться и установить VirtualBox на свой Мак или другие приложения для запуска среды Window. Пока, к сожалению, аналогов программы под Мак OS нет. И это, печалька.
Составляем семантическое ядро сайта с программой СловоЁБ
Сначала немного о самой программе СловоЁБ:
Это программа, предназначена для раскрутки и сео продвижения сайта. С ее помощью можно легко составить необходимый список ключевых слов, которые составят семантическое ядро сайта. Программа СловоЁБ абсолютно бесплатен и он предоставляет для Вас необходимый минимум, который нужен для работы с данными.
Программа СловоЁБ работает в системе Яндекс Wordstat. И поэтому для работы со СловоЁБ необходимо иметь аккаунт в Яндекс. Вся информация, спарсенная программой, автоматически сохраняется в созданном проекте и автоматически там сохраняется.
СловоЁБ предлагает своим пользователям ряд следующих функциональных возможностей:
– Работа в системе Яндекс Wordstat;
– Определение релевантных страниц сайта;
– Сбор базовой, уточняющей и морфологической частностей (Wordstat);
– Пакетный сбор данных из Яндекс Wordstat;
– Определение сезонности поисковых запросов из Wordstat;
– Сбор поисковых подсказок для сайта;
– Сбор информации о конкурентных запросах сайта в выдаче Яндекса и Google;
– Экспорт спарсенных данных в Excel.
И еще, кое-что …
Теперь давайте начнем работать с самой программой СловоЁБ.
Настраиваем программу СловоЁБ
Сначала нужно скачать саму программу. Это Вы сможете сделать прямо сейчас и совершенно бесплатно вот здесь:
Затем в скачанный архив нужно разархивировать и запустить файл Slovoeb, который запустит программу.
В открывшемся окошке программы вам нужно будет “Создать новый проект”
 Создать новый проект
Создать новый проект
Затем вам нужно войти в свой аккаунт в Яндекс, а если его нет, то завести его. Один совет! Работайте в программе не в своем основном аккаунте, а заведите лучше новый.
Теперь откройте вкладку “Настройки” и выберите здесь “Парсинг — Yandex.Direct”. Здесь введите свой логин и пароль в Яндекс.
Настройки
Есть еще важный момент: в настройках во вкладке “Yandex.Wordstat” нужно изменить параметр “Задержка между запросами” как на скриншоте.
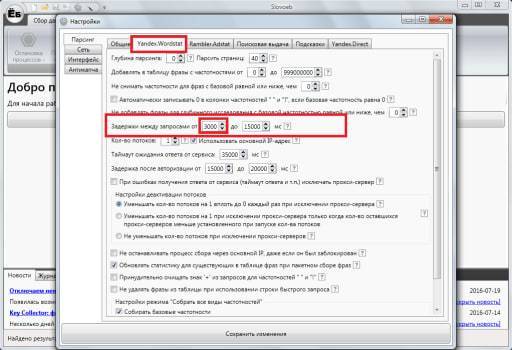 Задержка между запросами
Задержка между запросами
Остальные настройки можно настраивать под себя как вам будет угодно в зависимости от потребностей вашего проекта.
Узнаем как работать с программой СловоЁБ
Теперь давайте будем учиться работать в прогамме СловоЁБ и составим свое первое семантическое ядро сайта. Для этого в программе функции как и в Яндекс.Wordstat. Это сбор в левой колонке, в правой колонке Wordstat (“что еще искали…”), сбор частотностей. Но сейчас вы сможете собрать все нужные пакет ключевые слова нажав на одну кнопку. Но сначала необходимо составить список из нескольких самых значимых ключевых фраз, которые описывают страницу вашего сайта.
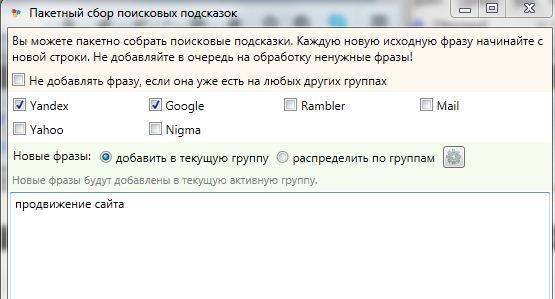
Жмем красную кнопку “Пакетный сбор фраз” в левой колонке Yandex.Wordstat и вписываем туда подобранные вами ключевые слова. Затем нажимаем кнопку «Начать сбор» и программа СловоЁБ приступит к сбору ключевиков в автоматическом режиме. Вообщем делайте как на скриншоте:
 Пакетный сбор фраз
Пакетный сбор фраз
После того, как сбор ключевых слов завешен,Вы можете приступить к сбору частотностей, вида «!» (для более точного вхождения ключевика) или «» (для вхождения по всем его словоформам).
Отсеять лишние фразы можно перед тем, как Вы сделаете сбор частотностей, а можно и после
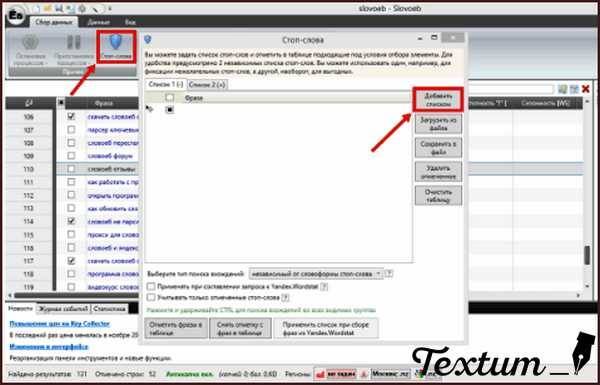
Это не столь важно. Чтобы упростить отбор ключевых слов и фраз, воспользуйтесь фильтром “Стоп-слова“
Например, у Вас лишними будут запросы содержащие слово “ошибка“. Внесите его в фильтр и нажмите “Отметить фразы в таблице“. И эти фразы будут отмечены галочкой в таблице для сбора. Затем их просто удалите.
 Стоп-слова
Стоп-слова
После того, как Вы убрали все лишнее можно скачать все собранные ключевые слова и фразы в Excel файл нажав на “Экспортировать данные“.
Какие дополнительные функции программы СловоЁБ?
Помимо основных функций по сбору семантического ядра сайта, есть еще дополнительные: сбор данных сезонности, вычисление KEI, анализ релевантных страниц, сбор позиций сайта в ПС.
Сезонность – указывает на зависимость количества запросов от времени года, месяца.
Показатель KEI – может указывает, по каким запросам из всего вашего списка ключевых слов и фраз лучше всего нужно продвигать ваш сайт. Значение KEI покажет вам, какие ключевые слова наиболее удачны для продвижения и по каким из них траффик будет выше, а конкуренция наоборот низкая.
Анализ релевантных страниц – поможет вам определить какие страницы наиболее подходят для заданного вами ключевого слова.
Сбор позиций в ПС укажет вам позицию сайта по определенному запросу.
Геозависимость – показывает частотность и другие значения по данному региону, который у Вас задан.
Если вам понравился материал пожалуйста сделайте следующее…
- Поставьте «лайк».
- Сделайте ретвит.
- И конечно же, оставьте свой комментарий ниже
Спасибо за внимание!
Всегда ваш Валерий Бородин
Ручной сбор СЯ
Весь процесс сбора семантического ядра можно условно разделить на несколько этапов. Каждый из них играет важную роль, поэтому крайне нежелательно что-то пропускать.
Шаг 1 – «мозговой штурм»
При ручном сборе семантики в первую очередь придется поднапрячь мозг. Откроем пустой текстовый документ и подумаем, какие подтемы (слова и словосочетания) есть в тематике копирайтинга. Например, «копирайтинг», «текст», «статья», «рерайтинг» и так далее. Записываем в столбик все варианты, которые придут в голову. Эта методика носит название «Мозговой штурм».

Не обязательно использовать только собственную фантазию. В поисках подтем можно отправиться на сайты конкурентов, там наверняка найдется что-то полезное.
Шаг 2 – Яндекс.Вордстат
Когда список подтем стал максимально емким, открываем старый добрый Яндекс.Вордстат. Впоследствии он поможет не только дополнить перечень ключевых слов, но и определить их «качество».
В строке ввода пишем первое слово из списка, нажимаем «Подобрать» и смотрим выдачу. Не забудьте отметить страну, в которой будете продвигать сайт.
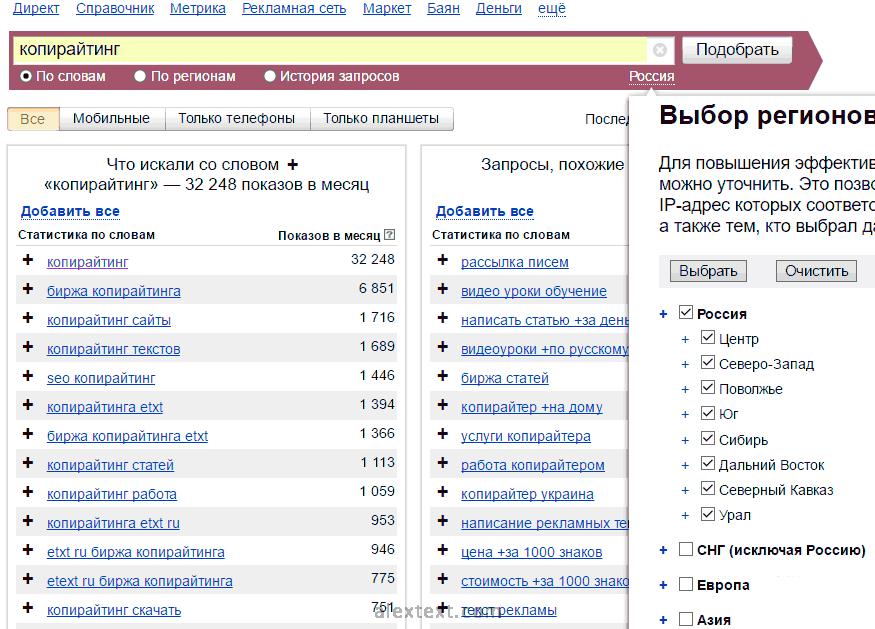
Итак, в левой колонке видим большой многостраничный перечень запросов, которые пользователи вводили в поисковую строку Яндекса за последний месяц. Цифры напротив них – общая частотность показов этих слов. В правой колонке выведены похожие запросы, которые нам и нужны. Выбираем оттуда актуальные фразы и добавляем в наш список. Например, пригодятся словосочетания «услуги копирайтера», «копирайтер Украина» (если вы будете продвигаться в Украине), «написание рекламных текстов», «цена за 1000 знаков», «стоимость за 1000 знаков», «текст рекламы». Аналогичные действия проводим со всеми словами из списка, включая фразы, которые подобрали через этот сервис. Увидите, как заметно расширится перечень.
Шаг 3 – поисковые подсказки
Еще один способ расширить список ключевых слов – поисковые подсказки. Просто вводим каждый запрос в строку поиска и записываем новые словесные конструкции по тематике сайта. Помните, фиксировать стоит все, что может иметь отношение к будущему ресурсу.
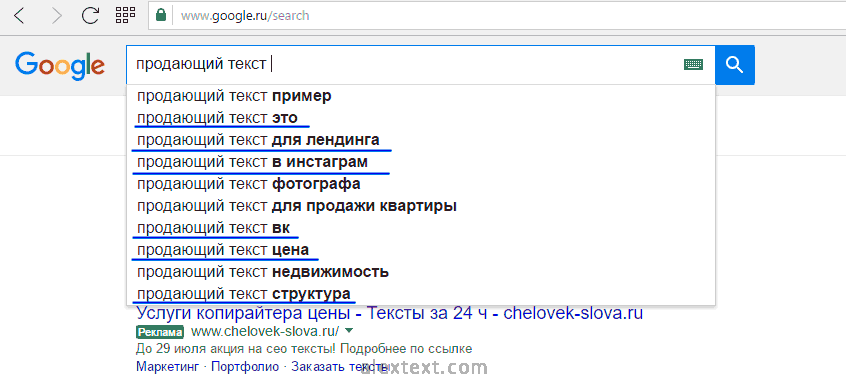

Не пугайтесь, когда заметите, что сидите за работой не первый час – так и есть. Ручной сбор семантики занимает очень много времени. Пожалуй, это один из самых длительных этапов создания сайта, но ваши бессонные ночи с лихвой окупятся.








Шаг 4 – аудит конкурентов
Поисковые запросы, по которым продвигаются конкуренты, могут еще немного дополнить список тематических слов и фраз. Если вы создаете коммерческий сайт с блогом, я рекомендую проводить работу в 2 этапа: позаимствовать ключи для коммерческих страниц, а затем для блога. Для начала понадобятся уже наполненные и успешно продвигающиеся сайты копирайтеров. Для парсинга информационных запросов лучше использовать тематические форумы. Почему именно форумы? Там пользователи задают актуальные вопросы, которые мы и стараемся узнать, чтобы впоследствии ответить на них в своем блоге.
Естественно, все делаем бесплатными средствами и для этого используем не безызвестную Сапу – она показывает наибольшее количество полезных запросов. Перед тем, как приступить к работе с сервисом, подбираем сайты, ключи которых хотелось бы посмотреть. Когда список интересных URL готов, регистрируемся на sape.ru и переходим в раздел «Оптимизатору».
Теперь создаем классический проект и как-нибудь его называем.
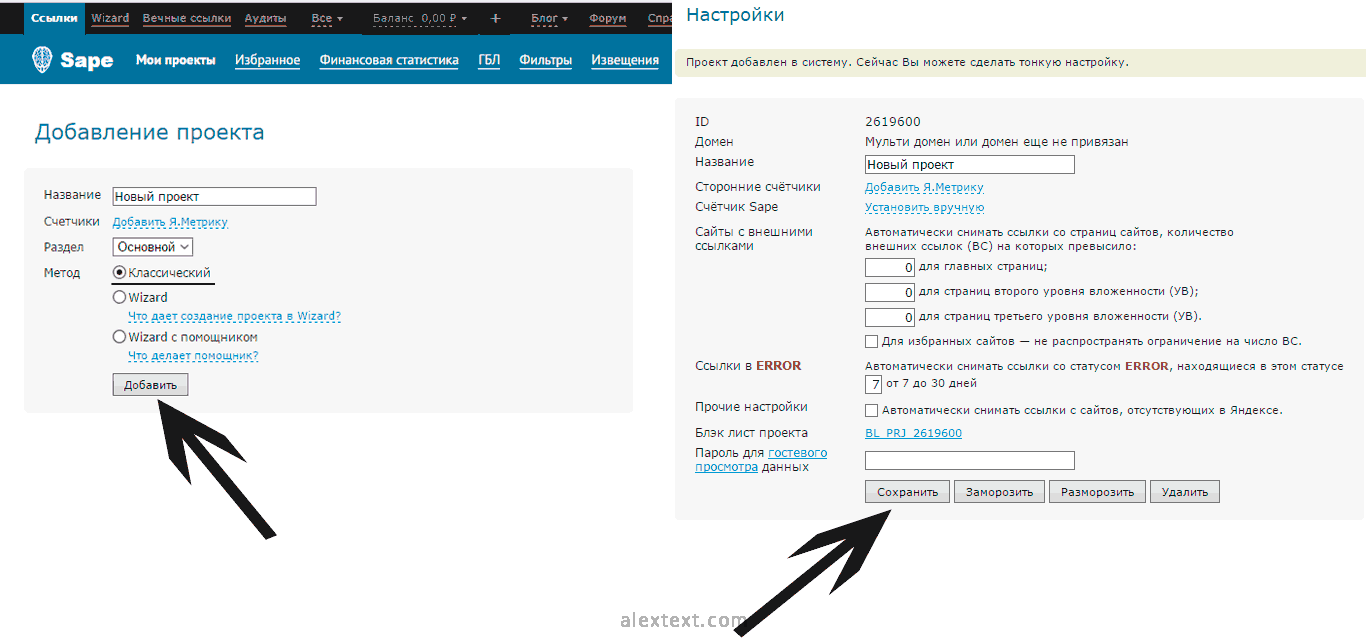
Когда проект создан, добавляем в базу URL первого интересующего сайта. Нажимаем «+», затем выбираем «URL».

Кликаем на кнопку «По позициям», вводим URL или домен нужного ресурса и нажимаем «Продолжить».
После этого сервис выдаст перечень ключевых слов, которые используются на предложенном сайте.
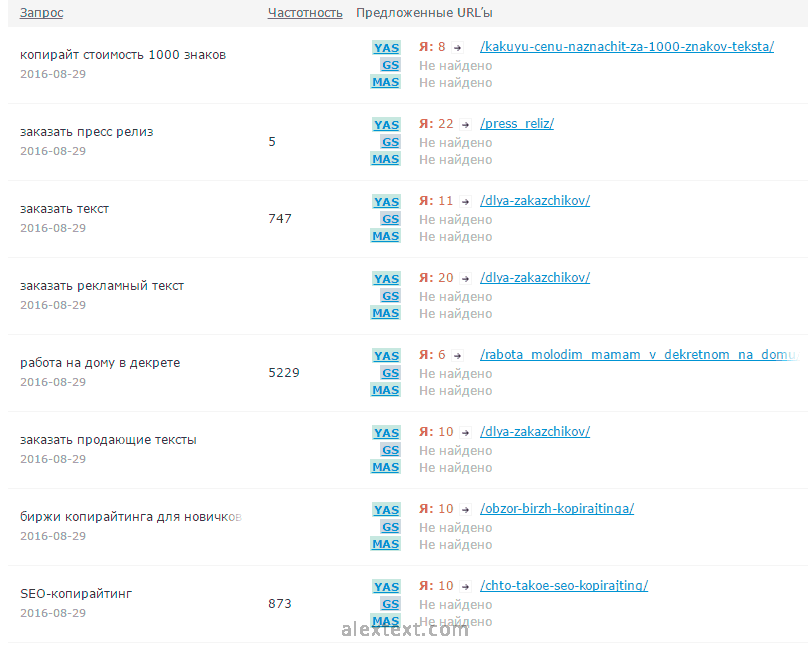
Выбираем все позиции и нажимаем «Продолжить» в правом нижнем углу. На следующей странице подтверждаем завершение формирования проекта. Таким образом, создается таблица поисковых запросов исследуемого конкурента. Если вы перейдете в раздел «Мои проекты»/«Оптимизатору», то увидите найденные ключи под созданным проектом, который до этого был пуст.
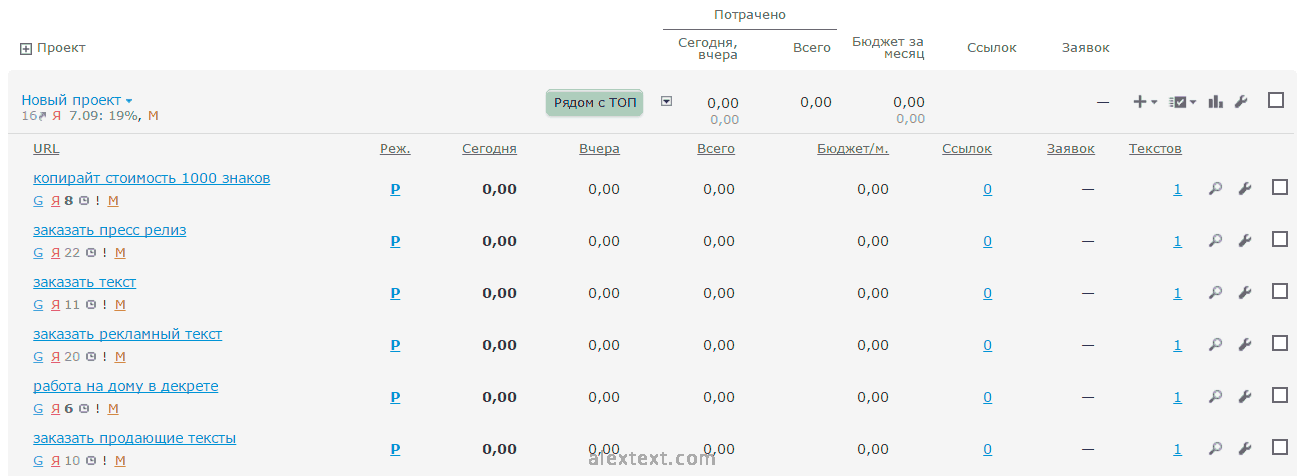
Аналогично создаем отдельные проекты под каждого конкурента. Затем переходим к работе с форумами.
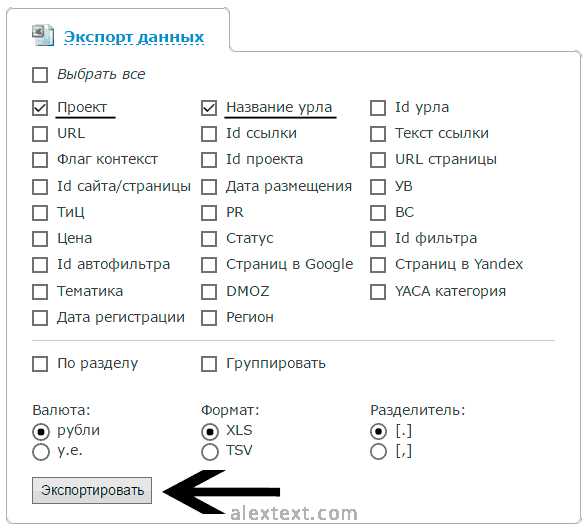
Чтобы не копировать вручную все ключи (после анализа нескольких ресурсов их количество может зашкалить за 1000), воспользуемся кнопкой экспорта данных в Excel. Наверняка вы уже заметили ее под проектами. Нажимаем и отмечаем галочками «Проект», «Название урла» и кликаем «Экспортировать». Затем сохраняем файл на ПК, он пригодится в дальнейшем.
Существуют и платные сервисы по анализу семантического ядра конкурентов, но их мы рассматривать не будем, поскольку эта статья посвящена исключительно бесплатному созданию сайта для портфолио копирайтера.